Every analysis starts with data and yields outputs. Managing Data is therefore a fundamental feature of ICRFS™. The brochure “Relational databases” (link) describes the way that ICRFS™ works with data and its extensive functionality for importing claims data into a database, organising, navigating in and managing the data.
ICRFS™ can work with client data in two fundamentally different ways: by importing data to an internal repository, and by using an external data source.
In the first mode, claims data is imported and stored internally in an ICRFS™ database, typically using the COM interface to communicate with the data source. This way of treating the data is also supported by the ICRFS™ Importer application and described in the ICRFS™ Importer brochure and Database brochure available here.
In the second mode, all the claims data are stored on a dedicated external data server. ICRFS™ connects to this server and obtains the data for analysis from it as required. The advantage of this is that the data is centrally managed by administrator, and is therefore always up-to-date and consistent across all users of ICRFS™. In many ways this arrangement is similar to what ICRFS™ Importer does, with the difference that rather than doing the importing once (a snapshot model), the live data is received from the server “on the fly” and is therefore guaranteed to be the latest update. When using this approach there is very little difference from the user's GUI perspective to using internally stored data. The user experience, including all the organisational elements, like Triangle Groups, Datasets, etc. remains the same.
Let us have a quick look at how ICRFS™ can use an external data source.
The first step is to define a connection to the external data server (Primary Server):
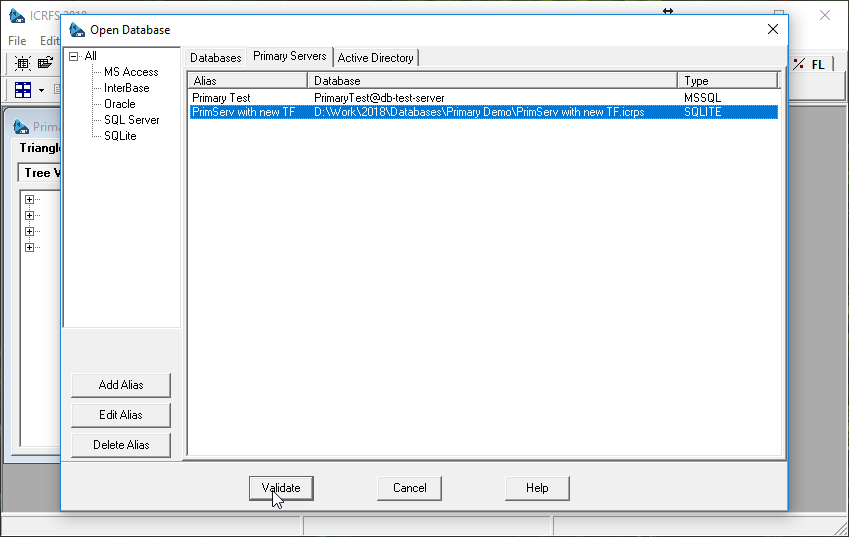
ICRFS™ has a special tab in the Open Database dialog that provides such definitions. This step is very similar to defining connections to ICRFS™ databases.
Suppose, we want to start with an empty database and get some data from the server. Let us open an empty database and choose a server to connect to:
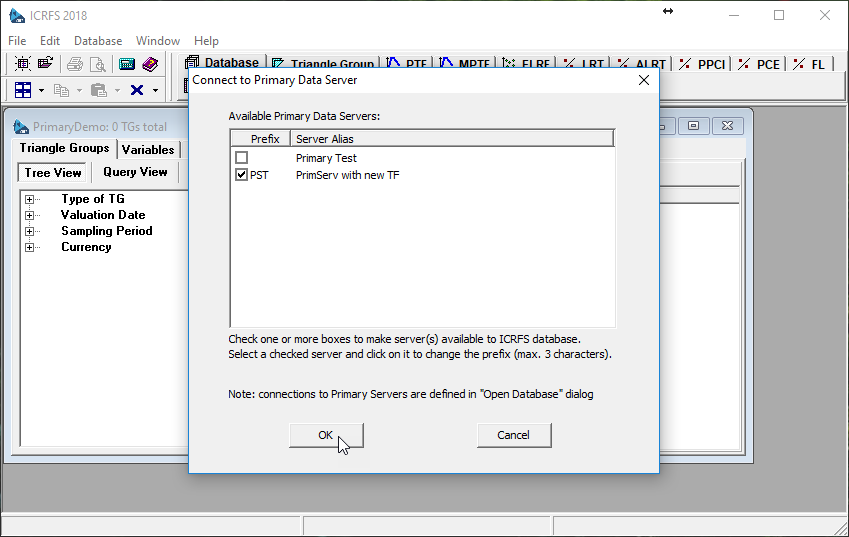
When we click OK, ICRFS™ connects to the server and creates TG Variables that will allow selections to be made from the data on the server. Now we are ready to create a Triangle Group connected to the server. In the following dialog we need to choose the key variables that identify the data:
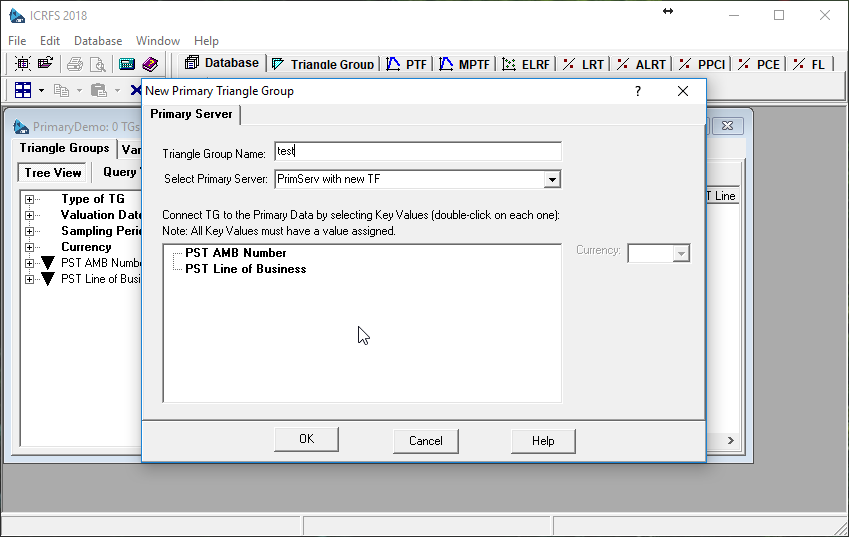
Double-click on each key, and the value selection dialog opens:
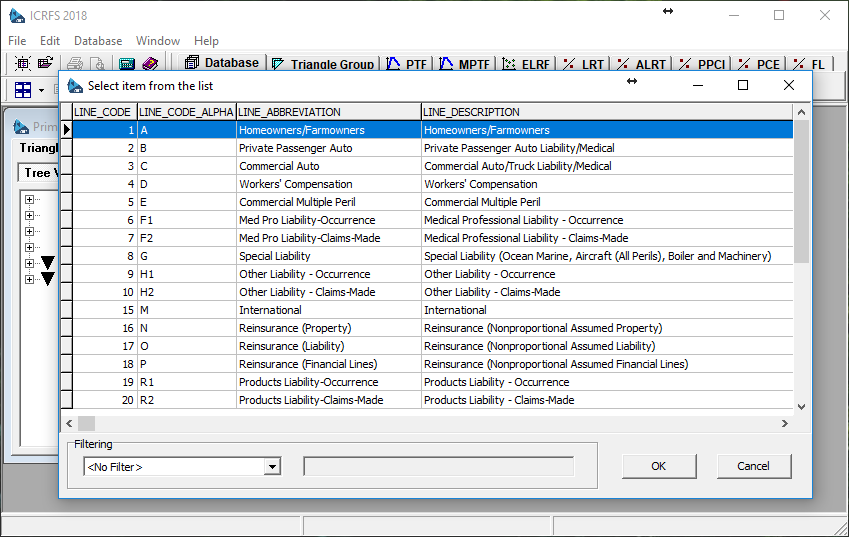
The data in this dialog comes directly from the server and assists in making the selection. Once all the selections are made, ICRFS™ creates a number of TG Variables that match the selection. We can now continue by giving a TG a name and adjusting its dimensions.
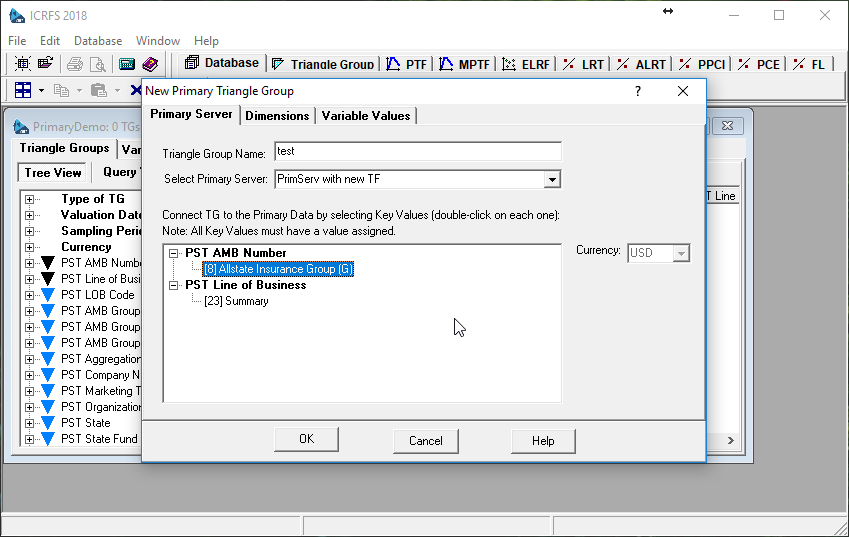
When we press OK a new TG is created and opened. We can now proceed to creating a new data triangle:
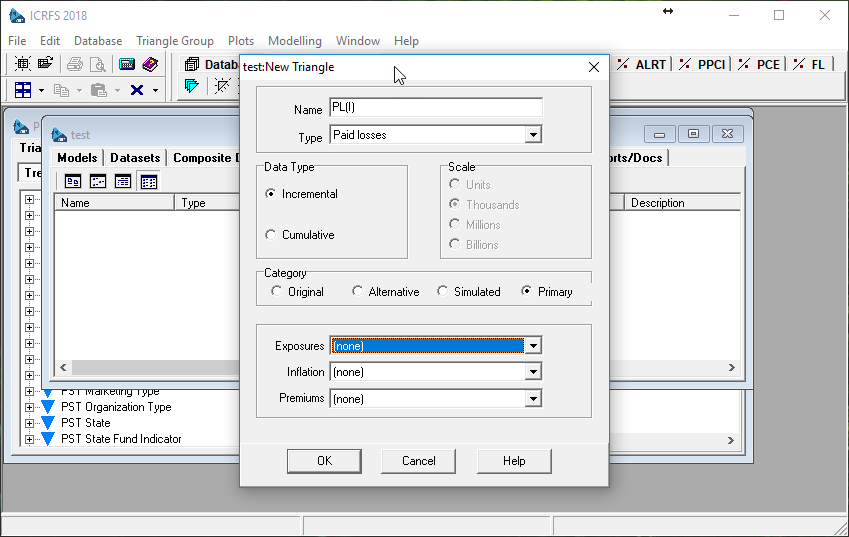
Suppose, we choose Paid Losses incremental triangle. Primary category is pre-selected, which means that the data is available on the server. Press OK, and:
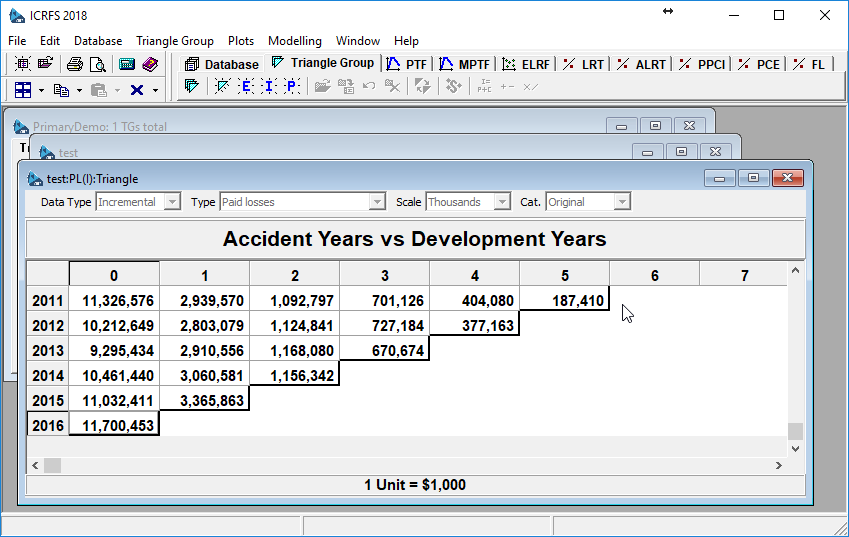
The triangle opens pre-populated with the data fetched from the server!
Remember, we started with an empty database, connected to the server, made a few selections and voila: we are ready to start analysis!
We followed the steps manually, however the “Wizards” will allow automatic creation of Primary Triangle Groups and triangles based on certain criteria. For instance, create everything that is available, or everything related to a particular company, or a particular line of business. This is how the database might look after the wizard has done its job:
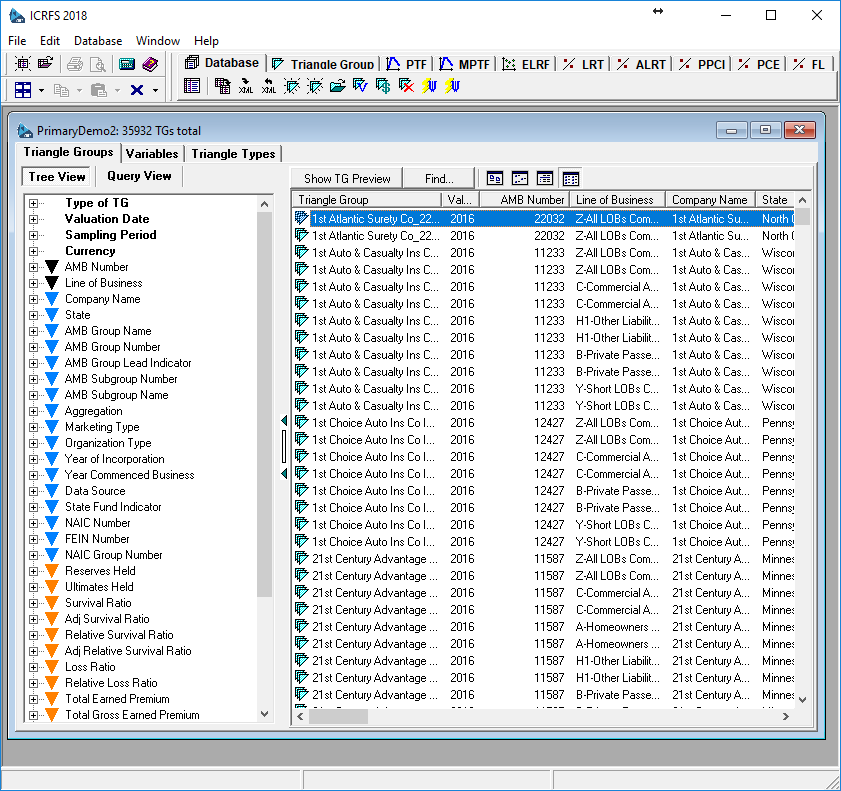
On every future occasion on which this database is opened it will automatically draw in the data from the original repository, but only for those units which are being worked with, as they are needed. This way the absolute minimum number of data transfers from the source is made each time.
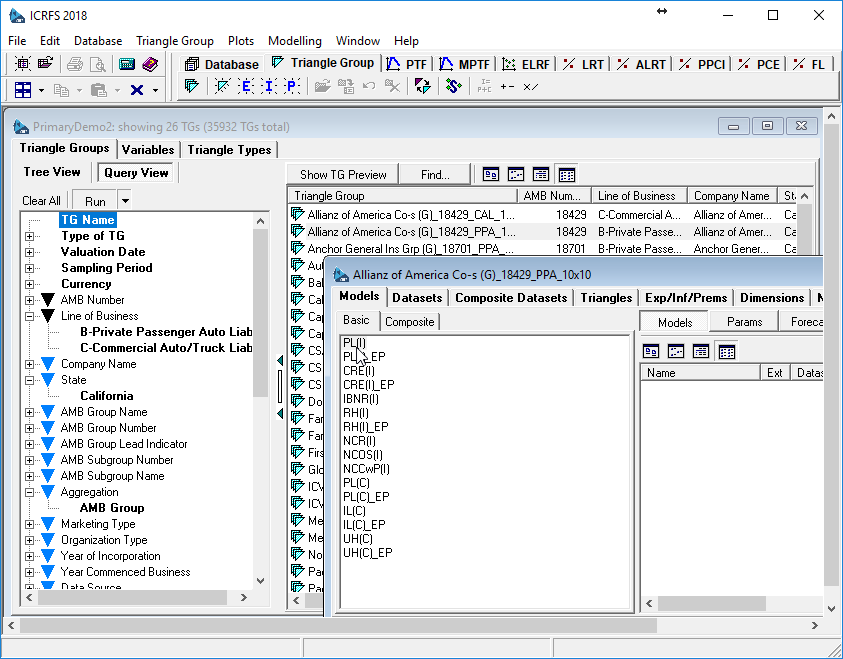
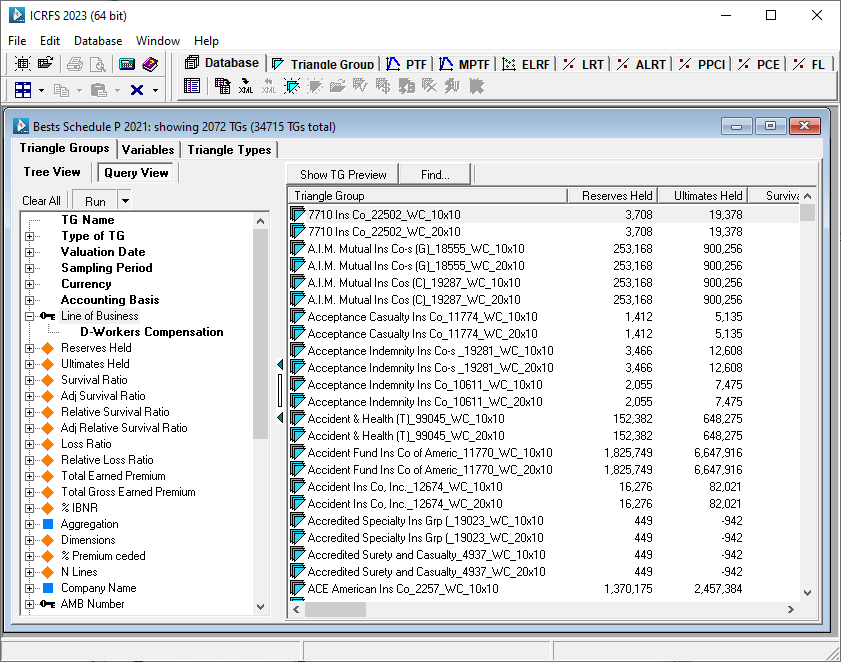
1. Navigation of triangle groups via tree view
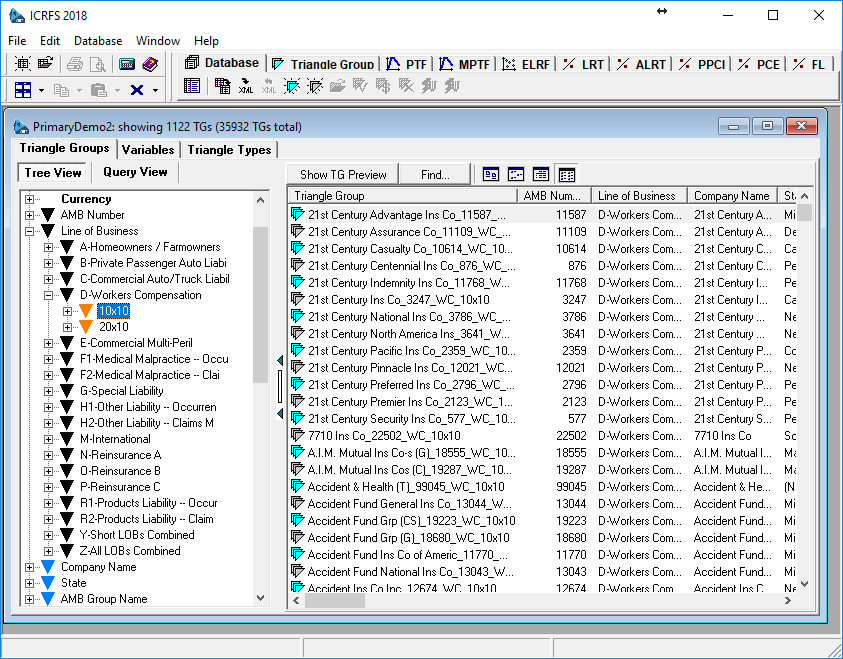
2. Navigation of triangle groups via query view and display of open triangle group contents