ICRFS™ databases are flexible
ICRFS™ databases offer enormous flexibility in how they are set up.
Over four thousand variables can be created to classify triangle groups.
Triangle Group names must be unique, but can contain up to 48 characters. Objects of the same type within triangle group (datasets, triangles, exposures, models, forecasts, etc) must have unique names. These names can be up to 40 characters long.
Databases should be organised to find information quickly
All ICRFS™ databases should be created so any user can find any triangle group within a few mouse clicks.
This is achieved by consistent application of classification variables and a good company naming convention. As a pleasant side-effect, consistent naming conventions make writing scripts utilising the COM API significantly easier to develop and maintain.
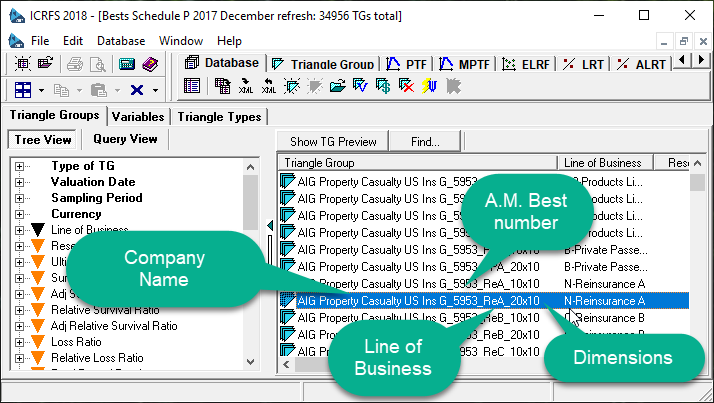
Case study: Best's Schedule P
The Best's Schedule P database (over 32000 triangle groups) is an Insureware example available to any purchaser of a Best's Schedule P subscription. Classifiers form the main filter of the database if exploring Best's Schedule P without a particular company in mind. If you are looking for a particular company, it can always be found within a few seconds.
The format of the Best's Schedule P triangle group naming convention is:
[Company Name (*)]_[AM Best Company Number]_[Line of Business Abbreviation]_[Dimensions: 10x10 or 20x10]
(*) If the limit of 48 characters is reached, then the company name may be truncated.
Within the Best's Schedule P triangle group the default abbreviations based on the data types are used - no additional naming standard is applied here.
An example utilising this naming convention is:
AIG Property Casualty US Ins G_5953_ReA_20x10
Case study: more detailed encoding
Naming standards for company's databases can encapsulate any level of coding as needed.
For instance, a more complex example might be a naming standard like the following:
- State [2 characters]
- Underwriting office [3 characters]
- Line of Business [3 characters]
- Basis [2 characters (eg: OY/AY/RY/UY)]
- AYs [12 characters to show start year (quarter) and end year(quarter)]
- CYs [12 characters to show start year (quarter) and end year(quarter)]
- Extraction date [4 characters to show date data was extracted from data warehouse]
- Sampling [2 characters]
To increase readability the categories are separated by a dash (note it's advisable not to use spaces in names to make it simpler for using the COM API).
Under this naming convention, a typical Triangle Group name would look like:
TX-T09-WC0-UY-90(01)18(04)-90(01)18(04)-1218-YQ
The name is fleshed out by 0's to enable the delimiters to be at exactly the same point - again for ease of external programming.
At a glance, one can tell without viewing all the variable assignments for the triangle group that: The data were for Texas, in underwriting office T09, for a Worker's Compensation portfolio, underwriting year basis, between 1Q/1990 and 4Q/2018 - without truncation, extracted in Dec-2018, on a Year by Quarter sampling.
Note in this naming standard it is assumed triangles are not truncated by development period. If this was a possibility then additional characters would be needed.
Naming conventions within a triangle group
Similarly naming conventions could apply to datasets, triangles, models, forecasts, or indeed any other database object according to company data categories or needs.
For instance, naming conventions for forecasts could look like: [Model abbreviation]_[Forecast Type]_[Modeler initials ]_[Date].
Eg for the final model chosen for this dataset, there are three forecasts:
- RSM_R01_MUN_141218
- RSM_C04_ODE_171218
- RSM_RSF_MUN_181218
Here for the naming conventions abbreviations used were:
For models:
- RSM = Reviewed selected model
- GXX = ith Good model for the data
For forecasts:
- RXX = ith Reasonable forecast
- RSF = Reviewed selected forecast
- CXX = ith Conservative forecast
While naming conventions from the user side are self-enforced, they are quick to implement and are easy to monitor with COM API tools.